- INFORMATIQUE - Formalisation et communication
- INFORMATIQUE - Formalisation et communicationL’information est partout présente dans notre existence. Les messages les plus variés ne cessent de nous parvenir de tous les points du globe, sous des formes de plus en plus diversifiées, au point que certains s’inquiètent de l’ampleur de ce flot où il devient de plus en plus malaisé de discerner l’essentiel de l’accessoire. Cet ouragan d’informations en provenance simultanée de tous les fronts place l’homme moderne dans une situation embarrassante, le laisse aussi perplexe que le mendiant brusquement propriétaire d’un palais et d’une nombreuse domesticité; comment concilier la lenteur des sens, la faible capacité d’absorption du cerveau, la brièveté de la vie avec la masse terrifiante des connaissances qui pourraient être utiles? Il est sans doute légitime d’espérer qu’un progrès de la pédagogie découlera un jour d’une connaissance plus approfondie du psychisme; toutefois il serait vain de croire que ce progrès puisse suffire pour que des individus isolés soient à même d’embrasser plus qu’une très faible partie de la connaissance actuellement partagée entre les nombreux membres de la communauté humaine. Dès lors, la nécessité d’accroître encore le potentiel de diffusion, de communication, de collecte des faits et des documents antérieurs apparaît impérieuse. La mémoire humaine est insuffisante, le savoir consigné dans les livres ne peut servir à quiconque si la consultation des ouvrages de plus en plus nombreux n’est pas rendue plus aisée par quelque méthode plus pratique et rapide que la recherche dans une bibliothèque. Les services d’information utilisant des mémoires électroniques se sont considérablement multipliés; déjà, dans de multiples applications (gestion de stocks, réservations de places d’avion...), les procédés traditionnels d’écriture ont été abandonnés. La pression même des faits oblige à apprendre de nouvelles techniques: transformer une image en message linéaire, un tableau de nombres en graphique, une dépêche en code, un code en langage clair; transposer le graphique sous forme phonétique; déchiffrer l’alphabet génétique; donner une description typologique objective d’empreintes digitales, de syndromes pathologiques; construire une maquette, un prototype à partir de schémas et passer d’un objet à une représentation planaire sans la lente intervention de dessinateurs ou de mécaniciens. Pour tous ces besoins, ces transmutations où l’information revêt de nouveaux visages adaptés à des destinataires usant de langages différents, il est indispensable que des techniques plus souples, plus rapides prennent la relève des humains pour qu’ils puissent consacrer plus de temps aux tâches essentielles que les machines ne peuvent accomplir. L’ordinateur n’est que le prolongement logique de la téléphonie, de la radiophonie, de la vidéophonie; son emploi s’impose dès qu’il importe de trier cette multitude de sons, de phrases, d’images, ce qui explique que la théorie de l’information doive ses acquisitions les plus remarquables aux recherches menées par une entreprise de télécommunications.Nature de l’informationL’usage a conféré au mot «information» un sens extrêmement étendu. Dire que l’information est partout présente signifie simplement que nous pouvons accroître nos connaissances par l’observation et l’analyse de tout objet ou de tout phénomène. Cette acceptation du terme livre cependant deux des propriétés fondamentales de l’information: elle ne peut exister sans support matériel, puisqu’elle doit être perçue ; il n’y a pas d’information sans récepteur, l’homme, animal ou machine, car elle doit être comprise pour mériter son nom.Ces deux aspects, forme et contenu (ou encore morphologie, structure et sémantique), sont liés par des relations encore mal connues, qui constituent précisément l’objet d’étude principal des sciences de l’information.En premier lieu, le contenu d’un message échappe à l’observation et ne peut être défini que d’une manière relative, comme un apport de renseignements. Dès lors que le message est reçu par plusieurs personnes il apparaît que la même forme peut véhiculer plusieurs contenus qui dépendent des connaissances antérieures des récepteurs. Par exemple, l’aspect d’une chaîne de montagne suggérera des idées très différentes au géologue, à l’économiste ou au touriste. Chacun d’eux en donnera une description singulière, soulignant des particularités qu’il considère comme primordiales et qui paraissent secondaires aux autres; chacun pourra choisir aussi, pour exprimer clairement son interprétation, une forme de message jugée appropriée: langues naturelles, tables de données chiffrées, photographies, cartes, etc. Le retentissement de chaque message sera, à son tour, variable selon l’expérience et l’intérêt de ceux à qui il parviendra.Un caractère commun à tous les messages est qu’ils constituent une représentation appauvrie de l’objet décrit, mais mettant par contre plus nettement en lumière les similitudes entre cet objet et certains autres. Sans cet appauvrissement, le passé pourrait être exactement reconstitué grâce aux témoignages, aux traces, aux empreintes qu’il a laissés; sans l’enrichissement associatif dû à l’aspect comparatif inhérent à tout symbolisme, la juxtaposition incohérente des faits successifs n’aurait donné naissance à aucune culture ni à aucune science.Ce qui est parfaitement attendu ou totalement inattendu n’est pas information: un événement aussi inéluctable que le coucher du soleil n’apprend rien à personne, une phrase prononcée dans une langue inconnue apparaît comme une suite aléatoire de sons dépourvus de sens. Un message ne sera donc perçu comme tel que pour autant qu’il obéit à certaines lois (par exemple, exploitation d’un vocabulaire et d’une syntaxe donnés) qui ont la double utilité d’en permettre le «décodage» et l’identification au sein d’un ensemble de «stimuli». Sans loi connue, il n’est nullement possible de discerner l’altération, ni a fortiori d’éliminer les erreurs dans une communication; le moindre parasite en modifie la signification; sans une certaine «liberté» dans le cadre de ces lois, aucun langage ne pourrait exprimer plus d’un seul message.Dans un inventaire aussi bref de la nature et des qualités de l’information, la notion de récepteur est à peine esquissée. En fin de course, le seul bénéficiaire d’une information sera toujours un homme ou une communauté humaine. Or l’étude de ce qu’on peut appeler la capacité d’absorption humaine en matière d’information montre que celle-ci n’est pas à la mesure de son appétit de connaissance. Les sens ne permettent pas de capter ce qui est trop petit ou trop grand, trop rapide ou trop lent; aussi les instruments doivent-ils pallier les déficiences de la faculté humaine de perception. Mais alors, la masse accrue de faits rendus perceptibles par voies indirectes se révèle trop considérable pour que le pouvoir de réflexion en tire tout le bénéfice souhaitable dans le bref laps d’existence qui est imparti à l’homme. Là encore les auxiliaires mécaniques sont indispensables pour exécuter les opérations simples de collecte, de présentation, de diffusion et quelques opérations d’analyse et de synthèse bien définies, afin de pouvoir reporter les efforts de réflexion et d’inspection de voies nouvelles dans les domaines où les machines n’apportent pas encore le moindre secours.La technologie de l’information concerne toutes les formes d’aide méthodologique ou matérielle permettant à l’homme de concentrer son attention sur les aspects les plus importants des messages. En ce sens, la technologie de l’information est apparue avec le langage parlé, puis avec l’écriture et le calcul. Les machines même ne sont pas récentes puisque les abaques, les bouliers constituaient déjà, il y a quelques milliers d’années, des outils assurant des fonctions importantes de traitement. Le recours à l’électronique a certes permis d’amplifier le rôle des machines dans le partage des tâches d’exécution pure, et de réaliser effectivement certains calculs hors de portée pour nos ancêtres, mais il n’y a pas de différence qualitative majeure entre les types de travaux réalisés à l’aide de grands ensembles électroniques, à l’aide de machines plus rudimentaires ou sans aide autre qu’une feuille de papier et un crayon. L’illusion que la puissance de jugement soit accrue parce que les robots fonctionnent avec une très grande célérité est fort répandue, bien qu’il suffise d’aborder quelques problèmes de nature combinatoire, qui se posent constamment dans la vie pratique, pour constater qu’il est strictement impossible de les résoudre par la simple énumération de toutes les combinaisons, même si l’on dispose des ordinateurs les plus puissants et les plus onéreux. Pourrait-on même asservir tous les atomes de l’Univers qu’ils ne suffiraient pas à représenter certains nombres que l’esprit conçoit sans peine. Les plus extraordinaires perfectionnements de matériel ne sauraient donc dispenser de rechercher sans cesse l’amélioration des méthodes, d’y apporter tous les raffinements possibles.Circulation de l’informationLes grands problèmes relatifs à l’information sont liés à sa collecte, son traitement, sa diffusion, sa conservation. L’état de développement des solutions varie grandement d’un secteur à l’autre. Une même question se pose à propos de la collecte ou de la diffusion: où trouver l’information utile, à qui convient-il de faire parvenir telle information connue? Les réponses à ce genre de préoccupations sont malheureusement encore largement empiriques ainsi qu’en témoignent la difficulté d’établir des statistiques, les sommes dépensées en enquêtes, les obstacles à la jonction harmonieuse de l’offre et de la demande dans le marché de l’information en pleine expansion. Les soins les plus méticuleux dans le recensement, la propagation la plus ingénieuse n’apportent pas la certitude que des sources ou des destinataires n’ont pas été oubliés. Notre goût pour l’efficience, notre amour de la rationalité s’offusquent de cette matière gaspillée, au point que nous ignorons même comment évaluer approximativement l’ordre de grandeur de la perte.Si nous ne savons pas aborder correctement ce problème de fond, un grand nombre de précieuses trouvailles allègent néanmoins notre peine à collecter ou à diffuser, et tend à accroître la fiabilité de ces opérations. La collecte fait une consommation croissante de capteurs (le domaine de la recherche médicale en offre l’exemple typique) qui évitent à l’homme de s’astreindre à guetter les événements. Les capteurs se composent essentiellement d’un appareil spécifiquement sensible à un type de phénomènes et d’un enregistreur permettant d’en consigner les variations constatées, dans un intervalle de temps, sur un support quelconque. On substitue parfois à l’enregistrement une liaison directe avec un ordinateur pour un traitement en «temps réel», c’est-à-dire une exploitation immédiate des données recueillies. Il n’est pas rare que les capteurs assument quelques fonctions de traitement, comme la «numérisation», c’est-à-dire la transformation d’une grandeur continue en grandeur discrète , pour en permettre une représentation chiffrée, et la réduction, c’est-à-dire le filtrage des parties du signal ne présentant qu’une variation attendue (un récepteur radiophonique agit comme un réducteur en éliminant l’onde porteuse pour ne restituer que les modulations à basse fréquence). Le filtrage est parfois une opération complexe (par exemple, l’épuration d’un électro-encéphalogramme qui rend compte de la combinaison d’activités électriques corticales et non corticales), voire impossible: ainsi, le degré de similitude entre deux images successives prises par une caméra de télévision est si élevé qu’il serait souhaitable de pouvoir ne transmettre que les différences entre elles. Cela impliquerait cependant que tout récepteur soit doté d’une mémoire capable de conserver une image complète; l’idée a néanmoins été partiellement appliquée dans le procédé Sécam de transmission et de reproduction des couleurs, où l’on néglige les différences d’intensité d’une couleur élémentaire sur deux lignes contiguës de l’image sans dégradation appréciable de sa qualité [cf. TÉLÉVISION].L’arsenal technologique de la diffusion d’information est vaste: procédés d’impression, de duplication, de transmission à distance, il semble inutile d’en faire la revue détaillée, d’autant plus que ces techniques constituent seulement le maillon terminal des circuits de l’information traitée par voies mécaniques. Par contre, il convient d’analyser plus précisément les techniques de transformation et de mémorisation de l’information qui paraissent souvent mystérieuses simplement parce qu’elles échappent à l’observation directe.Logique du calculOn ne saurait effectuer de traitement complexe de l’information sans user d’une mémoire. Si, par exemple, on désire calculer la somme de deux nombres, il faudra évidemment un mécanisme capable d’additionner, mais aussi deux registres, d’une nature matérielle quelconque, pour «contenir» ces nombres, et éventuellement un troisième pour stocker le résultat si l’on veut éviter la destruction des nombres initiaux pour une utilisation ultérieure. Un registre au minimum sera nécessaire si l’on suppose que l’un des termes de l’opération puisse être «introduit» au moment voulu, et que le résultat soit immédiatement «sorti» du calculateur, ou qu’il remplace en l’effaçant le second terme. Lorsque la capacité de mémorisation est faible, il ne peut être question d’effectuer plusieurs opérations sur les mêmes termes, ni d’envisager le traitement d’«êtres mathématiques» composés de plusieurs nombres (matrices, vecteurs, etc.). Par ailleurs, il est toujours nécessaire, quels que soient le problème traité et la machine disponible, de procéder à l’introduction des données, puis à l’extraction des résultats; il convient que ces échanges entre le milieu extérieur à la machine et son milieu interne soient réduits dans toute la mesure du possible, afin de minimiser sinon de supprimer les temps d’attente. Puisque les organes dits d’«entrée-sortie» sont forcément plus lents que les circuits internes du calculateur auquel ils sont connectés, on dote le calculateur de «mémoires-tampons» qui peuvent recevoir ou fournir une information aussi bien de l’«extérieur» que par les circuits de calcul, et cela à des cadences différentes et à des moments différents.La présence d’un organe de mémoire se révélant nécessaire dans tous les cas, il devient naturel d’exploiter la faculté de mémorisation pour améliorer le rendement des opérations de calcul et/ou pour en simplifier les mécanismes. Au niveau de la conception des circuits mêmes, des simplifications permettent de réaliser de précieuses économies de matériel: ainsi la multiplication peut être réduite à une succession d’additions avec des décalages appropriés, la soustraction peut être assimilée à l’addition avec «complémentation» préalable du facteur à soustraire, etc. Beaucoup de calculateurs ne contiennent en fait réellement qu’un mécanisme d’addition et en dérivent ingénieusement un ensemble complet d’opérations (les quatre opérations sur les nombres entiers, et, indépendamment, ces mêmes opérations sur les nombres fractionnaires avec exposant, dits «en virgule flottante»). Selon les modèles, le nombre d’instructions figurant au répertoire varie de 10 à 300 avec le fonds commun suivant: opérations d’entrée/sortie pour l’échange d’informations entre le calculateur et son environnement; opérations arithmétiques; opérations logiques de l’algèbre de Boole; opérations de comparaison.À partir de cet ensemble minimal de fonctions on peut construire des procédures plus complexes à condition de disposer d’une mémoire de taille suffisante. Plus cette dernière est vaste, plus il devient facile d’imaginer des méthodes de traitement efficientes, au point que certains problèmes ne peuvent être abordés si cette capacité de stockage est inférieure à un seuil donné.La mémoire d’un calculateur peut être comparée à un rayonnage de cases numérotées d’égales dimensions. Chaque article stocké doit avoir des dimensions au plus égales à celles d’une case et peut être retrouvé par son adresse qui est l’appellation technique de ce numéro. Lorsque l’adresse correspond à une localisation concrète déterminée, elle est dite absolue; par opposition, les adresses relatives donnent le numéro d’ordre d’une case (dénommée cellule, catène, mot...) par rapport à une origine, «adresse de base» qui est généralement la première (la plus basse en valeur numérique) d’un «bloc». Ce système de rétention des informations permet d’accéder à chacune d’entre elles à condition que l’adresse de rangement soit connue; par contre, il ne permet absolument pas de retrouver toutes les informations ayant une ou plusieurs propriétés formelles déterminées, comme par exemple «l’ensemble des entiers dont la valeur est comprise entre 103 et 104 漣 1»; une telle question ne pourra être résolue qu’en explorant exhaustivement les cases de la mémoire et en comparant successivement leur contenu avec les termes choisis.Cette démarche analytique n’est concevable, à partir d’une certaine taille de la mémoire, que s’il est indispensable de se procurer la réponse. De plus, la détermination d’une propriété formelle ne peut pas s’effectuer sur une partie de l’information; ainsi, dans une mémoire dont chaque case peut recevoir quatre lettres de l’alphabet, il sera relativement aisé de consulter une liste de noms propres pour extraire ceux qui commencent par Dupo , mais plus difficile de trouver ceux qui commencent par Dup , car il faudra en premier lieu «masquer» la quatrième lettre.Organisation du calculLa décomposition des tâches en étapes aussi infimes constitue elle-même une tâche qui tend à devenir écrasante si les objectifs visés impliquent l’exécution de plusieurs milliers d’opérations. La durée du travail préparatoire n’est pas linéairement proportionnelle au nombre d’instructions du programme, mais croît beaucoup plus vite, de sorte qu’il est prohibitif de consacrer dans la pratique un temps aussi long à l’élaboration finale de résultats vérifiés.Le traitement de l’information suppose une hiérarchisation des tâches: de petits groupes d’instructions du répertoire permettront de définir des fonctions jusqu’alors inexistantes; ces fonctions pourront dès lors être considérées comme des instructions normales, et les éléments du répertoire ainsi enrichi seront à nouveau combinés entre eux pour bâtir des fonctions plus complexes, etc. Cette structuration organique est évidemment plus facile à maîtriser qu’une grande quantité d’instructions toutes placées au même niveau hiérarchique. Les machines abstraites que sont les programmes ont une existence bien réelle, et il serait plus approprié de les considérer comme des machines fugitives momentanément logées dans la mémoire du calculateur.Cette volatilité constitutionnelle des programmes permet de les surimposer au gré des besoins à une même machine physique qui assume de la sorte une très grande variété de tâches; elle permet en outre, et c’est sans doute là une conquête essentielle, aux programmes de se modifier eux-mêmes parce qu’il n’y a pas de différence de nature entre les données et les instructions et que toute transformation concevable des informations mémorisées s’applique aussi bien aux unes qu’aux autres. On atteint ici le concept de machine malléable, donc potentiellement évolutive et perfectible sans intervention extérieure, dans la mesure toutefois où l’on pourra définir formellement des fonctions de perfectibilité, ce qui relève de l’art de la cybernétique.Par souci de clarté, on a évoqué en premier lieu la technique de constitution pyramidale d’un ensemble de fonctions, bien qu’il soit toujours nécessaire dans la pratique d’aborder auparavant les problèmes exposés sous une forme plus ou moins synthétique en procédant à leur analyse, c’est-à-dire en appliquant le célèbre principe cartésien de la décomposition d’une difficulté en parcelles. On ne peut guère parler d’une méthodologie de l’analyse, sinon pour souhaiter qu’elle rattrape dans son développement celle de la programmation. On peut illustrer les rapports qui existent entre l’analyse et la synthèse par des formules symboliques.Tout travail de traitement de l’information consiste à appliquer un ensemble d’opération de traitement O à un ensemble d’antécédents A en vue d’obtenir un ensemble de conséquents C:
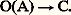 La synthèse consiste à imaginer et effectivement constituer O et à l’appliquer à A dans le but de rechercher C, qui est inconnu par définition:
La synthèse consiste à imaginer et effectivement constituer O et à l’appliquer à A dans le but de rechercher C, qui est inconnu par définition: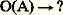 L’analyse consite au contraire à rechercher, connaissant une transformation de A en C, l’ensemble inconnu d’opérations pour y parvenir:
L’analyse consite au contraire à rechercher, connaissant une transformation de A en C, l’ensemble inconnu d’opérations pour y parvenir: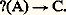 Ce dernier problème n’a pas de solution générale connue; sinon on disposerait d’une méthode permettant «de trouver le moyen» d’obtenir n’importe quelles conclusions à partir de n’importe quelles prémisses.Les deux types de problèmes peuvent être soumis aux hommes ou aux machines elles-mêmes. L’art de construire des programmes automatiquement, l’algorithmique, a donné naissance en particulier à des «générateurs» de programmes ou de sous-programmes, capables de constituer à la demande des séquences d’opérations et d’assembler des sous-programmes en vue d’un calcul déterminé. Ainsi, des générateurs de tri d’un emploi très courant peuvent fabriquer des programmes optimisés à partir de simples indications sur les types de tri désirés et quelques paramètres décrivant le matériel de traitement.L’art d’élaborer automatiquement des méthodes de traitement, ou heuristique, pourrait se définir comme une tentative de rendre les machines «intelligentes». Aucun gadget électronique ne saurait dispenser d’avoir à rechercher au préalable quels sont les mécanismes de l’intelligence, ou d’inventer au moins des mécanismes éventuellement différents mais capables des mêmes performances. Bien que les progrès de l’heuristique soient lents et n’aient pas donné lieu à des applications pratiques, il faut néanmoins mentionner quelques réussites dans ce domaine de recherche: on a pu obtenir la démonstration automatique de théorèmes de la géométrie plane ou soumettre une machine à des tests d’aptitudes psychotechniques (par exemple, «donner le premier élément manquant des séries 1, 3, 5, 7, ..., 1, 2, 4, 8, ..., 1, 2, 3, 5, 8, ...») avec succès.Si, comme le proclament les auteurs de ces recherches, l’intelligence ne peut être définie autrement que par ses effets extérieurs, on peut affirmer qu’un premier pas dans la conquête de la pensée a été franchi. Cette position pragmatique est fort controversée, et il est impossible de rendre compte, à propos de technologie de l’information, de ce débat encore ouvert, où les arguments métaphysiques et moraux ne sont pas exclus.Langages de programmationLes besoins de la technologie de l’information ont contribué, dès l’origine, à la création de langages artificiels spécialement conçus pour faciliter les tâches et leur définition. Ces langages à leur tour ont permis d’entreprendre des travaux plus ambitieux et des applications si élaborées que de nouveaux langages plus perfectionnés que les premiers ont vu le jour depuis lors. Ces aides réciproques de la problématique et des langages ont également contribué à leur diversification puisqu’il existe des centaines de langages artificiels qui offrent de curieuses similitudes avec les langues naturelles: ils évoluent un peu indépendamment de notre volonté et on y trouve des familles, des branches ayant des liens de parenté plus ou moins étroits.Le recensement de tous les aspects de ces langages est sans doute d’ores et déjà impossible, et l’on n’indiquera ici que quelques caractères fondamentaux communs à la plupart d’entre eux, ainsi que les grandes lignes de leur développement.Le premier langage algorithmique vraiment évolué, le Fortran (acronyme de for mula tran slation), fut créé au début des années cinquante; il reste, dans ses différentes versions, très employé pour le calcul scientifique et est même parfois utilisé dans des applications de gestion. L’idée maîtresse du Fortran consiste à bannir dans toute la mesure du possible les références à une machine particulière, en utilisant des notations d’un usage universel. Par exemple, l’ordre A = B + C, qui signifie «faire la somme algébrique des valeurs des variables B et C et imposer la valeur trouvée à la variable A», ne demande pas un grand effort d’apprentissage étant donné son analogie avec le symbolisme mathématique le plus familier. Toute machine dotée d’un «compilateur» Fortran (c’est-à-dire d’un programme destiné à passer de cette forme symbolique universelle à une forme interne, directement exécutable par cette machine ou par une autre du même type et, éventuellement, de type différent) pourra traiter un problème défini dans le langage. Toutes les personnes connaissant ce langage pourront échanger entre elles leurs méthodes de résolution (même, à la limite, si elles ne parlent pas la même langue naturelle). Tout sous-programme écrit en langage Fortran, par quiconque, pourra être distribué et incorporé comme sous-ensemble d’autres programmes aussi variés que l’on voudra. La normalisation d’un tel langage sert donc un triple objectif de communication: il relie d’abord les hommes entre eux, puis il permet une relation entre les hommes et les machines, enfin il fait communiquer les machines entre elles.Il était naturel de chercher à enrichir et à perfectionner un outil aussi précieux à partir d’un noyau initial de fonctions. Deux voies s’ouvrent pour cet enrichissement: les macro-instructions et les sous-programmes indépendants. Le recours à l’une ou à l’autre de ces solutions dépend en général de considérations sur l’efficacité des programmes d’exécution (en principe l’emploi de macro-instructions tend à produire des programmes plus encombrants, mais permettant un traitement plus rapide que leurs équivalents exploitant une logique de sous-programmes).Si par exemple une fonction du type ax + b se révèle très récurrente dans un calcul, il est possible de lui associer un nom (par exemple «PREMIE») en donnant au préalable l’équivalence entre ce label arbitraire et la structure voulue:
Ce dernier problème n’a pas de solution générale connue; sinon on disposerait d’une méthode permettant «de trouver le moyen» d’obtenir n’importe quelles conclusions à partir de n’importe quelles prémisses.Les deux types de problèmes peuvent être soumis aux hommes ou aux machines elles-mêmes. L’art de construire des programmes automatiquement, l’algorithmique, a donné naissance en particulier à des «générateurs» de programmes ou de sous-programmes, capables de constituer à la demande des séquences d’opérations et d’assembler des sous-programmes en vue d’un calcul déterminé. Ainsi, des générateurs de tri d’un emploi très courant peuvent fabriquer des programmes optimisés à partir de simples indications sur les types de tri désirés et quelques paramètres décrivant le matériel de traitement.L’art d’élaborer automatiquement des méthodes de traitement, ou heuristique, pourrait se définir comme une tentative de rendre les machines «intelligentes». Aucun gadget électronique ne saurait dispenser d’avoir à rechercher au préalable quels sont les mécanismes de l’intelligence, ou d’inventer au moins des mécanismes éventuellement différents mais capables des mêmes performances. Bien que les progrès de l’heuristique soient lents et n’aient pas donné lieu à des applications pratiques, il faut néanmoins mentionner quelques réussites dans ce domaine de recherche: on a pu obtenir la démonstration automatique de théorèmes de la géométrie plane ou soumettre une machine à des tests d’aptitudes psychotechniques (par exemple, «donner le premier élément manquant des séries 1, 3, 5, 7, ..., 1, 2, 4, 8, ..., 1, 2, 3, 5, 8, ...») avec succès.Si, comme le proclament les auteurs de ces recherches, l’intelligence ne peut être définie autrement que par ses effets extérieurs, on peut affirmer qu’un premier pas dans la conquête de la pensée a été franchi. Cette position pragmatique est fort controversée, et il est impossible de rendre compte, à propos de technologie de l’information, de ce débat encore ouvert, où les arguments métaphysiques et moraux ne sont pas exclus.Langages de programmationLes besoins de la technologie de l’information ont contribué, dès l’origine, à la création de langages artificiels spécialement conçus pour faciliter les tâches et leur définition. Ces langages à leur tour ont permis d’entreprendre des travaux plus ambitieux et des applications si élaborées que de nouveaux langages plus perfectionnés que les premiers ont vu le jour depuis lors. Ces aides réciproques de la problématique et des langages ont également contribué à leur diversification puisqu’il existe des centaines de langages artificiels qui offrent de curieuses similitudes avec les langues naturelles: ils évoluent un peu indépendamment de notre volonté et on y trouve des familles, des branches ayant des liens de parenté plus ou moins étroits.Le recensement de tous les aspects de ces langages est sans doute d’ores et déjà impossible, et l’on n’indiquera ici que quelques caractères fondamentaux communs à la plupart d’entre eux, ainsi que les grandes lignes de leur développement.Le premier langage algorithmique vraiment évolué, le Fortran (acronyme de for mula tran slation), fut créé au début des années cinquante; il reste, dans ses différentes versions, très employé pour le calcul scientifique et est même parfois utilisé dans des applications de gestion. L’idée maîtresse du Fortran consiste à bannir dans toute la mesure du possible les références à une machine particulière, en utilisant des notations d’un usage universel. Par exemple, l’ordre A = B + C, qui signifie «faire la somme algébrique des valeurs des variables B et C et imposer la valeur trouvée à la variable A», ne demande pas un grand effort d’apprentissage étant donné son analogie avec le symbolisme mathématique le plus familier. Toute machine dotée d’un «compilateur» Fortran (c’est-à-dire d’un programme destiné à passer de cette forme symbolique universelle à une forme interne, directement exécutable par cette machine ou par une autre du même type et, éventuellement, de type différent) pourra traiter un problème défini dans le langage. Toutes les personnes connaissant ce langage pourront échanger entre elles leurs méthodes de résolution (même, à la limite, si elles ne parlent pas la même langue naturelle). Tout sous-programme écrit en langage Fortran, par quiconque, pourra être distribué et incorporé comme sous-ensemble d’autres programmes aussi variés que l’on voudra. La normalisation d’un tel langage sert donc un triple objectif de communication: il relie d’abord les hommes entre eux, puis il permet une relation entre les hommes et les machines, enfin il fait communiquer les machines entre elles.Il était naturel de chercher à enrichir et à perfectionner un outil aussi précieux à partir d’un noyau initial de fonctions. Deux voies s’ouvrent pour cet enrichissement: les macro-instructions et les sous-programmes indépendants. Le recours à l’une ou à l’autre de ces solutions dépend en général de considérations sur l’efficacité des programmes d’exécution (en principe l’emploi de macro-instructions tend à produire des programmes plus encombrants, mais permettant un traitement plus rapide que leurs équivalents exploitant une logique de sous-programmes).Si par exemple une fonction du type ax + b se révèle très récurrente dans un calcul, il est possible de lui associer un nom (par exemple «PREMIE») en donnant au préalable l’équivalence entre ce label arbitraire et la structure voulue: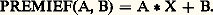 Dès lors, ce nom, ou label, est acquis au répertoire et permet d’écrire, par exemple:
Dès lors, ce nom, ou label, est acquis au répertoire et permet d’écrire, par exemple: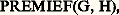 au lieu de G X + H;
au lieu de G X + H;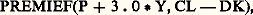 au lieu de (P + 3 練 0 Y) X + CL 漣 DK;
au lieu de (P + 3 練 0 Y) X + CL 漣 DK;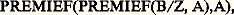 au lieu de (B/Z X + A) X + A. Cette forme d’écriture met plus nettement en lumière la nature de la séquence d’opérations. En se basant sur la macro-opération PREMIE, on pourra définir:
au lieu de (B/Z X + A) X + A. Cette forme d’écriture met plus nettement en lumière la nature de la séquence d’opérations. En se basant sur la macro-opération PREMIE, on pourra définir: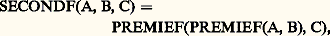 ce qui ajoute un symbole au répertoire et permet éventuellement de réduire la troisième expression de l’exemple à:
ce qui ajoute un symbole au répertoire et permet éventuellement de réduire la troisième expression de l’exemple à: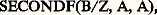 qui correspond à la même séquence de calcul avec un excellent isomorphisme dans l’énoncé des coefficients de la fonction du second degré.Si, primitivement, des opérations ainsi définies ne pouvaient correspondre qu’à une séquence de calcul exprimable par une suite d’instructions arithmétiques, il est maintenant aisé de créer des séquences de calculs quelconques (par exemple, «trouver la valeur absolue de la différence maximale entre deux variables prises dans une table de n nombres») et de les baptiser. Il est même possible de créer des structures variant en fonction de conditions mémorisées au fur et à mesure que le programme symbolique est analysé et traduit par l’ordinateur, afin de réduire l’encombrement du programme résultant et d’en rendre le déroulement plus rapide par suppression de séquences d’opérations inutiles.Les progrès dans la synthèse ont été plus rapides que ceux de l’analyse, et s’il est facile de donner un contenu à un symbole, il paraît moins simple de modifier les lois syntaxiques assez rigides des langages artificiels. La plus connue des formalisations permettant d’énoncer les règles syntaxiques d’un langage artificiel est la notation de Backus employée systématiquement pour la définition du langage Algol et de ses dérivés nombreux: Jovial , Formac , etc. Cette notation permet de nommer des formes syntaxiques en donnant leur description en termes des éléments et des formes qu’elles contiennent.À partir de la syntaxe initiale de Backus, on peut constuire des expressions très diverses dans leur morphologie, et ce système peut être exploité par un compilateur pour reconnaître les entités syntaxiques contenues dans une expression donnée. Ce symbolisme a grandement simplifié la logique et la construction de nouveaux compilateurs; il ne paraît pas, par contre, avoir été utilisé pour définir progressivement un langage en cours de calcul, pour le modifier éventuellement. Il n’existe pas non plus, à notre connaissance, de définitions conditionnelles des formes, alors qu’un mécanisme les rendant possibles pourrait être précieux, notamment pour les études de traduction automatique.ApplicationsLes mécanismes de traitement de l’information décrits ci-dessus se sont perfectionnés à mesure que les calculateurs devenaient plus rapides et plus efficients. Il est aujourd’hui inconcevable qu’un ordinateur soit capable d’exécuter uniquement les fonctions câblées dans sa structure matérielle, et chaque nouvelle machine doit être conçue avec une bibliothèque de programmes permettant d’en étendre l’usage à des applications très diverses. On ne saurait citer tous les domaines où l’emploi d’ordinateurs a pratiquement supplanté les hommes dans leur travail (le mieux connu étant celui de la comptabilité de toute entreprise dépassant une certaine taille), ni les secteurs où ils prennent la relève de personnels voués à des tâches ingrates de surveillance: l’aspect quantitatif et social de compression d’un personnel peu qualifié à été très souvent évoqué avec beaucoup d’exagération à propos de l’implantation de systèmes informatiques, certains voyant dans cette évolution une révolution analogue à celle qui provoqua les profonds remous du début du machinisme. La comparaison n’est guère justifiée car, si les machines mues par une énergie de combustion se sont révélées très avantageuses pour libérer l’homme de peines et de fatigues musculaires, les ordinateurs électroniques ne peuvent aucunement se substituer à l’homme pour exercer à sa place la domination du monde par l’intelligence. Bien au contraire, les reconversions qu’implique l’avènement de l’informatique nous conduisent à mieux réfléchir sur nos méthodes de travail et souvent à les modifier au lieu de nous conformer à des habitudes profondément ancrées: l’exécution d’une tâche est facilitée par un travail préparatoire qui en organise minutieusement les étapes successives; ce principe bien connu de l’action réfléchie, de la décision mûrement pesée n’oblige pourtant pas dans la vie pratique à codifier, à planifier ou à prévoir les plus infimes détails d’une action; on peut d’ordinaire se fier à l’intuition ou au sens des responsabilités, à la volonté de parvenir à un but bien défini pour modifier ses actes en fonction de circonstances rares ou difficiles à prévoir; les directives concernant la poursuite d’un objectif précis peuvent habituellement être formulées en quelques phrases qui dessinent les grandes lignes que l’on s’est fixées sans spécifier les moyens exacts qui seront nécessaires. Il en va bien différemment lorsqu’on décide de confier une tâche, même très banale, à un ordinateur qui est doté de quelques fonctions élémentaires de jugement et d’appréciation, mais qui se trouve à la fois dépourvu de sensibilité et d’expérience: le moindre oubli, la moindre altération de l’information qu’il traite ne le détourne nullement d’appliquer les procédures de calcul valables dans les cas normaux à ces renseignements aberrants, même si des résultats exacts doivent être détruits et remplacés par des suites de signes dépourvues de sens. Un contrôle de la validité des résultats s’impose donc, puisque la probabilité qu’une information soit inexacte n’est pour ainsi dire jamais nulle. Toutefois la conséquence la plus importante de cet état de choses est qu’on ne peut espérer se débarrasser d’un travail quelconque sans avoir au préalable élucidé tous les cas particuliers qui peuvent faire obstacle à sa réalisation; et cet inventaire exhaustif des difficultés rencontrées dans la solution d’un problème conduit souvent à réviser complètement la manière de procéder habituelle et à définir des démarches à la fois plus simples et plus générales. Ainsi la comptabilité sur ordinateur d’une grande entreprise n’est-elle pas la simple transposition des opérations classiques de tenue de livres en partie double, mais bien plus une refonte complète de la logique comptable à l’aide d’opérations «intégrées» où chaque mouvement de compte est considéré à des points de vue infiniment variés: montant, provenance, destination, incidences sur les stocks, les investissements, les commandes, les transports, les disponibilités financières, etc., avec une mise à jour permanente et simultanée de tous les dossiers: clients, fournisseurs, stocks, bilans, statistiques chronologiques et géographiques... À l’inverse de ce que l’on pourrait supposer, la multiplicité des opérations effectuées sur une même donnée de base ne constitue pas un facteur d’alourdissement du système comptable, mais une rentabilisation amélioré de la machine de calcul qui, dans un laps de temps pratiquement équivalent, peut fournir un, plusieurs ou tous les types de renseignements énoncés ci-dessus; et cette charge est assumée selon des normes qualitativement inégalées, puisque l’estimation de la marche d’une affaire peut désormais se fonder sur l’analyse quotidienne de la situation, ainsi que sur des extrapolations à court ou à long terme dérivées par l’ordinateur des mêmes données. Dans la pratique, la surveillance automatique des stocks minimaux, le lancement automatique de commandes de réapprovisionnement, le rappel de factures non payées sont les embryons de systèmes beaucoup plus vastes qui présentent de moins en moins de résultats accessoires et un nombre bien plus élevé de documents essentiels pour des décisions majeures.Il était naturel que l’évolution rapprochant les consommateurs d’information les plus importants et les matériels de traitement influençât à son tour la configuration des ordinateurs: le «cerveau» électronique qui digère les renseignements peut être caché en quelque cave ou quelque lointaine banlieue, mais il faut le doter de prolongements permettant de communiquer directement et instantanément avec les utilisateurs, par le moyen de consoles, de claviers, d’écrans cathodiques. La centralisation des moyens de calcul puissants permet leur interconnection, la continuité des services rendus malgré les pannes possibles, une meilleur exploitation des possibilités de chaque machine, une répartition plus rationnelle des demandes, un entretien plus efficace; la dispersion des «unités terminales» assure une meilleure accessibilité au matériel, une réduction de l’attente d’un renseignement, une incitation accrue pour chacun d’avoir recours au services de l’ordinateur. Ces raisons expliquent en partie le succès de systèmes fédéraux de traitement de l’information qui ressemblent par bien des aspects aux systèmes nerveux des êtres vivants: cortex très excentré et ramifications arborescentes. Les changements ne concernent pas uniquement ces dispositions matérielles: les langages formels sont devenus «conversationnels», c’est-à-dire qu’ils permettent de formuler les problèmes en questions et en réponses et d’orienter les recherches en fonction des résultats partiels déjà donnés. Parmi les applications les plus spectaculaires, il convient de mentionner en particulier l’usage des ordinateurs dans l’enseignement et dans la recherche. Le problème essentiel de l’enseignement peut être brièvement schématisé en disant qu’il y a peu de maîtres et beaucoup d’élèves tous différents: dans ces conditions, comment est-il possible d’adapter le rythme d’enseignement aux individus, et comment contrôler leurs progrès, leurs échecs, la nature des difficultés qu’ils rencontrent? Bien que les tâches ici demandées aux ordinateurs soient trop complexes pour que les solutions actuelles soient optimales, de nombreuses réalisations pratiques ont déjà montré que certaines difficultés inhérentes aux méthodes traditionnelles d’enseignement, notamment la faiblesse des communications entre maîtres et élèves, peuvent être vaincues à l’aide des ordinateurs; non seulement chacun pourra revoir et réentendre aussi souvent qu’il le désire les points du cours enregistré qui lui paraissent les plus ardus, et cela à l’heure de son choix sans que s’ensuive aucune perturbation du travail de ses condisciples; mais ces questions, ces demandes posées par chaque élève en particulier seront elles-mêmes enregistrées, collectées, triées pour que les auteurs de cours disposent de meilleurs éléments pour le réviser. De très nombreux systèmes ont ainsi vu le jour pour «interconnecter» les travaux de centaines ou de milliers de chercheurs scientifiques, chacun disposant à son gré de «tranches» de calcul automatique pour la mise au point de ses méthodes propres et l’exploitation de ses données personnelles; dès que l’un des participants est satisfait des résultats qu’il a obtenus, il peut rendre sa méthode «publique», c’est-à-dire que chaque autre participant sera, au moment le plus propice, averti par le système de l’existence d’un nouveau programme; plusieurs personnes peuvent éventuellement travailler sur le même programme dans sa phase d’essai et se transmettre des messages par l’intermédiaire d’une immense mémoire partagée, ce qui délivre chacun du souci, classique au téléphone, de trouver l’interlocuteur au moment de l’appel. Cet affranchissement des contraintes temporelles a parfois d’heureux effets sur la qualité même des messages; il est en effet plus facile d’expliquer une chose lorsque l’on est conscient que l’explication parviendra en temps utile à des destinataires disposés à l’écouter et à l’examiner que lorsque l’on est contraint d’entrer en contact avec des interlocuteurs que l’on dérange parfois. Docile secrétaire, l’ordinateur peut également le cas échéant délivrer des contraintes spatiales et mettre en contact avec un correspondant sans que l’on ait besoin de savoir où il se trouve; là encore, il suffit que la mémoire puisse associer des noms et des adresses et modifier le contenu de ces tables à la demande des intéressés.L’interaction de l’homme et de l’ordinateur a trouvé une voie particulièrement heureuse dans le développement de systèmes conversationels concernant les secteurs les plus variés. Ainsi, la création de nouveaux modèles d’automobiles est facilitée par l’usage d’écrans cathodiques permettant l’introduction, la transformation et la restitution d’informations graphiques; il suffit aux ingénieurs de dessiner schématiquement les éléments qu’ils désirent assembler pour obtenir des plans exacts, visibles selon n’importe quel angle de projection avec un agrandissement quelconque; ces réponses graphiques sont assorties de résultats de calcul concernant toutes les valeurs paramétriques de l’objet créé (dimensions, poids, moments d’inertie, énergie consommée ou produite, prix des éléments, etc.); en fonction de ces résultats préliminaires, les ingénieurs peuvent modifier diverses données du montage initialement prévu et connaître immédiatement l’incidence de ces changements, ce qui rend aisé l’abandon de solutions qui se sont révélées médiocres et une recherche plus minutieuse dans les voies les plus fructueuses. Ici encore l’amélioration purement quantitative des délais apporte un bénéfice qualitatif dans l’exécution du projet.Un autre domaine riche en réalisations est celui des simulateurs: avant l’avènement de moyens de calcul électronique il était difficile, voire impossible, de reproduire ou d’imiter des systèmes complexes aux lois connues par des moyens simples. Ainsi, il est exclu que toutes les données expérimentales concernant un barrage hydraulique puissent être déduites de l’étude d’une maquette reproduisant l’ouvrage projeté en dimensions réduites; en effet, si l’on adopte par exemple une échelle de 1:20 pour cette reproduction, les surfaces seront réduites à 1:400 de l’original et les volumes, les masses à 1:8 000 de ce qu’elles devraient être. Dans ces conditions, les conclusions déduites de l’examen d’une telle maquette, par elle-même d’une réalisation longue et délicate, sont – quoique utiles – très partielles et insuffisantes; par contre il est extrêmement aisé de fournir à un ordinateur les éléments de calcul concernant toutes les réactions possibles d’un système réel en vrai grandeur afin de mieux en étudier les particularités. La vitesse de traitement des informations permet en outre d’observer le comportement d’un système proposé comme modèle pendant une période très longue: le trafic d’un port maritime pendant vingt ans ou l’évolution d’une population pendant dix générations. La facilité avec laquelle des mécanisnes connus sont simulés a incité certains chercheurs à tenter de formuler des hypothèses biologiques, physiologiques, sociologiques sous forme de «modèles mathématiques» simples dans leur principe, mais impliquant une très grande quantité d’opérations de calcul et dont les variations ne peuvent pour cette raison être étudiées et comparées aux observations du monde réel sans l’aide d’ordinateurs. À cette classe de recherches il convient d’associer les techniques de classification automatique, de taxinomie, qui tentent de dégager les lois structurelles associant les «propriétés» des objets les plus divers: textes littéraires pour caractériser les composantes stylistiques propres à chaque auteur, observations médicales pour établir des tableaux cliniques appropriés à la formulation d’un diagnostic, voire même d’un pronostic, etc. Pour des recherches de ce genre l’ordinateur constitue un indispensable outil pour la pensée créatrice qu’il prolonge et concrétise en élucidant les plus infimes conséquences des prémisses proposées.L’emploi des ordinateurs continue à gagner de nouveaux domaines; on sait maintenant qu’il peut apporter une aide aux problèmes d’urbanisme, d’aménagement du territoire, et également à des questions politiques (découpages électoraux, organisation du pouvoir exécutif) ou judiciaires (recherches de jurisprudence, etc.).Il serait prématuré de tirer des conclusions philosophiques ou sociales du fait qu’aucun acte de la vie des hommes n’échappera bientôt à une certaine prévision technique, et d’en tirer la prédiction pessimiste que les maléfices de l’électronique seront plus forts que les bienfaits. Il convient plutôt de regarder avec lucidité cet avenir où le traitement de l’information jouera un rôle encore plus étendu (ne serait-ce que pour des raisons économiques) afin d’assurer que l’usage en sera le meilleur.
qui correspond à la même séquence de calcul avec un excellent isomorphisme dans l’énoncé des coefficients de la fonction du second degré.Si, primitivement, des opérations ainsi définies ne pouvaient correspondre qu’à une séquence de calcul exprimable par une suite d’instructions arithmétiques, il est maintenant aisé de créer des séquences de calculs quelconques (par exemple, «trouver la valeur absolue de la différence maximale entre deux variables prises dans une table de n nombres») et de les baptiser. Il est même possible de créer des structures variant en fonction de conditions mémorisées au fur et à mesure que le programme symbolique est analysé et traduit par l’ordinateur, afin de réduire l’encombrement du programme résultant et d’en rendre le déroulement plus rapide par suppression de séquences d’opérations inutiles.Les progrès dans la synthèse ont été plus rapides que ceux de l’analyse, et s’il est facile de donner un contenu à un symbole, il paraît moins simple de modifier les lois syntaxiques assez rigides des langages artificiels. La plus connue des formalisations permettant d’énoncer les règles syntaxiques d’un langage artificiel est la notation de Backus employée systématiquement pour la définition du langage Algol et de ses dérivés nombreux: Jovial , Formac , etc. Cette notation permet de nommer des formes syntaxiques en donnant leur description en termes des éléments et des formes qu’elles contiennent.À partir de la syntaxe initiale de Backus, on peut constuire des expressions très diverses dans leur morphologie, et ce système peut être exploité par un compilateur pour reconnaître les entités syntaxiques contenues dans une expression donnée. Ce symbolisme a grandement simplifié la logique et la construction de nouveaux compilateurs; il ne paraît pas, par contre, avoir été utilisé pour définir progressivement un langage en cours de calcul, pour le modifier éventuellement. Il n’existe pas non plus, à notre connaissance, de définitions conditionnelles des formes, alors qu’un mécanisme les rendant possibles pourrait être précieux, notamment pour les études de traduction automatique.ApplicationsLes mécanismes de traitement de l’information décrits ci-dessus se sont perfectionnés à mesure que les calculateurs devenaient plus rapides et plus efficients. Il est aujourd’hui inconcevable qu’un ordinateur soit capable d’exécuter uniquement les fonctions câblées dans sa structure matérielle, et chaque nouvelle machine doit être conçue avec une bibliothèque de programmes permettant d’en étendre l’usage à des applications très diverses. On ne saurait citer tous les domaines où l’emploi d’ordinateurs a pratiquement supplanté les hommes dans leur travail (le mieux connu étant celui de la comptabilité de toute entreprise dépassant une certaine taille), ni les secteurs où ils prennent la relève de personnels voués à des tâches ingrates de surveillance: l’aspect quantitatif et social de compression d’un personnel peu qualifié à été très souvent évoqué avec beaucoup d’exagération à propos de l’implantation de systèmes informatiques, certains voyant dans cette évolution une révolution analogue à celle qui provoqua les profonds remous du début du machinisme. La comparaison n’est guère justifiée car, si les machines mues par une énergie de combustion se sont révélées très avantageuses pour libérer l’homme de peines et de fatigues musculaires, les ordinateurs électroniques ne peuvent aucunement se substituer à l’homme pour exercer à sa place la domination du monde par l’intelligence. Bien au contraire, les reconversions qu’implique l’avènement de l’informatique nous conduisent à mieux réfléchir sur nos méthodes de travail et souvent à les modifier au lieu de nous conformer à des habitudes profondément ancrées: l’exécution d’une tâche est facilitée par un travail préparatoire qui en organise minutieusement les étapes successives; ce principe bien connu de l’action réfléchie, de la décision mûrement pesée n’oblige pourtant pas dans la vie pratique à codifier, à planifier ou à prévoir les plus infimes détails d’une action; on peut d’ordinaire se fier à l’intuition ou au sens des responsabilités, à la volonté de parvenir à un but bien défini pour modifier ses actes en fonction de circonstances rares ou difficiles à prévoir; les directives concernant la poursuite d’un objectif précis peuvent habituellement être formulées en quelques phrases qui dessinent les grandes lignes que l’on s’est fixées sans spécifier les moyens exacts qui seront nécessaires. Il en va bien différemment lorsqu’on décide de confier une tâche, même très banale, à un ordinateur qui est doté de quelques fonctions élémentaires de jugement et d’appréciation, mais qui se trouve à la fois dépourvu de sensibilité et d’expérience: le moindre oubli, la moindre altération de l’information qu’il traite ne le détourne nullement d’appliquer les procédures de calcul valables dans les cas normaux à ces renseignements aberrants, même si des résultats exacts doivent être détruits et remplacés par des suites de signes dépourvues de sens. Un contrôle de la validité des résultats s’impose donc, puisque la probabilité qu’une information soit inexacte n’est pour ainsi dire jamais nulle. Toutefois la conséquence la plus importante de cet état de choses est qu’on ne peut espérer se débarrasser d’un travail quelconque sans avoir au préalable élucidé tous les cas particuliers qui peuvent faire obstacle à sa réalisation; et cet inventaire exhaustif des difficultés rencontrées dans la solution d’un problème conduit souvent à réviser complètement la manière de procéder habituelle et à définir des démarches à la fois plus simples et plus générales. Ainsi la comptabilité sur ordinateur d’une grande entreprise n’est-elle pas la simple transposition des opérations classiques de tenue de livres en partie double, mais bien plus une refonte complète de la logique comptable à l’aide d’opérations «intégrées» où chaque mouvement de compte est considéré à des points de vue infiniment variés: montant, provenance, destination, incidences sur les stocks, les investissements, les commandes, les transports, les disponibilités financières, etc., avec une mise à jour permanente et simultanée de tous les dossiers: clients, fournisseurs, stocks, bilans, statistiques chronologiques et géographiques... À l’inverse de ce que l’on pourrait supposer, la multiplicité des opérations effectuées sur une même donnée de base ne constitue pas un facteur d’alourdissement du système comptable, mais une rentabilisation amélioré de la machine de calcul qui, dans un laps de temps pratiquement équivalent, peut fournir un, plusieurs ou tous les types de renseignements énoncés ci-dessus; et cette charge est assumée selon des normes qualitativement inégalées, puisque l’estimation de la marche d’une affaire peut désormais se fonder sur l’analyse quotidienne de la situation, ainsi que sur des extrapolations à court ou à long terme dérivées par l’ordinateur des mêmes données. Dans la pratique, la surveillance automatique des stocks minimaux, le lancement automatique de commandes de réapprovisionnement, le rappel de factures non payées sont les embryons de systèmes beaucoup plus vastes qui présentent de moins en moins de résultats accessoires et un nombre bien plus élevé de documents essentiels pour des décisions majeures.Il était naturel que l’évolution rapprochant les consommateurs d’information les plus importants et les matériels de traitement influençât à son tour la configuration des ordinateurs: le «cerveau» électronique qui digère les renseignements peut être caché en quelque cave ou quelque lointaine banlieue, mais il faut le doter de prolongements permettant de communiquer directement et instantanément avec les utilisateurs, par le moyen de consoles, de claviers, d’écrans cathodiques. La centralisation des moyens de calcul puissants permet leur interconnection, la continuité des services rendus malgré les pannes possibles, une meilleur exploitation des possibilités de chaque machine, une répartition plus rationnelle des demandes, un entretien plus efficace; la dispersion des «unités terminales» assure une meilleure accessibilité au matériel, une réduction de l’attente d’un renseignement, une incitation accrue pour chacun d’avoir recours au services de l’ordinateur. Ces raisons expliquent en partie le succès de systèmes fédéraux de traitement de l’information qui ressemblent par bien des aspects aux systèmes nerveux des êtres vivants: cortex très excentré et ramifications arborescentes. Les changements ne concernent pas uniquement ces dispositions matérielles: les langages formels sont devenus «conversationnels», c’est-à-dire qu’ils permettent de formuler les problèmes en questions et en réponses et d’orienter les recherches en fonction des résultats partiels déjà donnés. Parmi les applications les plus spectaculaires, il convient de mentionner en particulier l’usage des ordinateurs dans l’enseignement et dans la recherche. Le problème essentiel de l’enseignement peut être brièvement schématisé en disant qu’il y a peu de maîtres et beaucoup d’élèves tous différents: dans ces conditions, comment est-il possible d’adapter le rythme d’enseignement aux individus, et comment contrôler leurs progrès, leurs échecs, la nature des difficultés qu’ils rencontrent? Bien que les tâches ici demandées aux ordinateurs soient trop complexes pour que les solutions actuelles soient optimales, de nombreuses réalisations pratiques ont déjà montré que certaines difficultés inhérentes aux méthodes traditionnelles d’enseignement, notamment la faiblesse des communications entre maîtres et élèves, peuvent être vaincues à l’aide des ordinateurs; non seulement chacun pourra revoir et réentendre aussi souvent qu’il le désire les points du cours enregistré qui lui paraissent les plus ardus, et cela à l’heure de son choix sans que s’ensuive aucune perturbation du travail de ses condisciples; mais ces questions, ces demandes posées par chaque élève en particulier seront elles-mêmes enregistrées, collectées, triées pour que les auteurs de cours disposent de meilleurs éléments pour le réviser. De très nombreux systèmes ont ainsi vu le jour pour «interconnecter» les travaux de centaines ou de milliers de chercheurs scientifiques, chacun disposant à son gré de «tranches» de calcul automatique pour la mise au point de ses méthodes propres et l’exploitation de ses données personnelles; dès que l’un des participants est satisfait des résultats qu’il a obtenus, il peut rendre sa méthode «publique», c’est-à-dire que chaque autre participant sera, au moment le plus propice, averti par le système de l’existence d’un nouveau programme; plusieurs personnes peuvent éventuellement travailler sur le même programme dans sa phase d’essai et se transmettre des messages par l’intermédiaire d’une immense mémoire partagée, ce qui délivre chacun du souci, classique au téléphone, de trouver l’interlocuteur au moment de l’appel. Cet affranchissement des contraintes temporelles a parfois d’heureux effets sur la qualité même des messages; il est en effet plus facile d’expliquer une chose lorsque l’on est conscient que l’explication parviendra en temps utile à des destinataires disposés à l’écouter et à l’examiner que lorsque l’on est contraint d’entrer en contact avec des interlocuteurs que l’on dérange parfois. Docile secrétaire, l’ordinateur peut également le cas échéant délivrer des contraintes spatiales et mettre en contact avec un correspondant sans que l’on ait besoin de savoir où il se trouve; là encore, il suffit que la mémoire puisse associer des noms et des adresses et modifier le contenu de ces tables à la demande des intéressés.L’interaction de l’homme et de l’ordinateur a trouvé une voie particulièrement heureuse dans le développement de systèmes conversationels concernant les secteurs les plus variés. Ainsi, la création de nouveaux modèles d’automobiles est facilitée par l’usage d’écrans cathodiques permettant l’introduction, la transformation et la restitution d’informations graphiques; il suffit aux ingénieurs de dessiner schématiquement les éléments qu’ils désirent assembler pour obtenir des plans exacts, visibles selon n’importe quel angle de projection avec un agrandissement quelconque; ces réponses graphiques sont assorties de résultats de calcul concernant toutes les valeurs paramétriques de l’objet créé (dimensions, poids, moments d’inertie, énergie consommée ou produite, prix des éléments, etc.); en fonction de ces résultats préliminaires, les ingénieurs peuvent modifier diverses données du montage initialement prévu et connaître immédiatement l’incidence de ces changements, ce qui rend aisé l’abandon de solutions qui se sont révélées médiocres et une recherche plus minutieuse dans les voies les plus fructueuses. Ici encore l’amélioration purement quantitative des délais apporte un bénéfice qualitatif dans l’exécution du projet.Un autre domaine riche en réalisations est celui des simulateurs: avant l’avènement de moyens de calcul électronique il était difficile, voire impossible, de reproduire ou d’imiter des systèmes complexes aux lois connues par des moyens simples. Ainsi, il est exclu que toutes les données expérimentales concernant un barrage hydraulique puissent être déduites de l’étude d’une maquette reproduisant l’ouvrage projeté en dimensions réduites; en effet, si l’on adopte par exemple une échelle de 1:20 pour cette reproduction, les surfaces seront réduites à 1:400 de l’original et les volumes, les masses à 1:8 000 de ce qu’elles devraient être. Dans ces conditions, les conclusions déduites de l’examen d’une telle maquette, par elle-même d’une réalisation longue et délicate, sont – quoique utiles – très partielles et insuffisantes; par contre il est extrêmement aisé de fournir à un ordinateur les éléments de calcul concernant toutes les réactions possibles d’un système réel en vrai grandeur afin de mieux en étudier les particularités. La vitesse de traitement des informations permet en outre d’observer le comportement d’un système proposé comme modèle pendant une période très longue: le trafic d’un port maritime pendant vingt ans ou l’évolution d’une population pendant dix générations. La facilité avec laquelle des mécanisnes connus sont simulés a incité certains chercheurs à tenter de formuler des hypothèses biologiques, physiologiques, sociologiques sous forme de «modèles mathématiques» simples dans leur principe, mais impliquant une très grande quantité d’opérations de calcul et dont les variations ne peuvent pour cette raison être étudiées et comparées aux observations du monde réel sans l’aide d’ordinateurs. À cette classe de recherches il convient d’associer les techniques de classification automatique, de taxinomie, qui tentent de dégager les lois structurelles associant les «propriétés» des objets les plus divers: textes littéraires pour caractériser les composantes stylistiques propres à chaque auteur, observations médicales pour établir des tableaux cliniques appropriés à la formulation d’un diagnostic, voire même d’un pronostic, etc. Pour des recherches de ce genre l’ordinateur constitue un indispensable outil pour la pensée créatrice qu’il prolonge et concrétise en élucidant les plus infimes conséquences des prémisses proposées.L’emploi des ordinateurs continue à gagner de nouveaux domaines; on sait maintenant qu’il peut apporter une aide aux problèmes d’urbanisme, d’aménagement du territoire, et également à des questions politiques (découpages électoraux, organisation du pouvoir exécutif) ou judiciaires (recherches de jurisprudence, etc.).Il serait prématuré de tirer des conclusions philosophiques ou sociales du fait qu’aucun acte de la vie des hommes n’échappera bientôt à une certaine prévision technique, et d’en tirer la prédiction pessimiste que les maléfices de l’électronique seront plus forts que les bienfaits. Il convient plutôt de regarder avec lucidité cet avenir où le traitement de l’information jouera un rôle encore plus étendu (ne serait-ce que pour des raisons économiques) afin d’assurer que l’usage en sera le meilleur.
Encyclopédie Universelle. 2012.